

Lifespan Age Transformation Synthesis
We address the problem of single photo age progression and regression -- the prediction of how a person might look in the future, or how they looked in the past. Most existing aging methods are limited to changing the texture, overlooking transformations in head shape that occur during the human aging and growth process. This limits the applicability of previous methods to aging of adults to slightly older adults, and application of those methods to photos of children does not produce quality results. We propose a novel multi-domain image-to-image generative adversarial network architecture, whose learned latent space models a continuous bi-directional aging process. The network is trained on the FFHQ dataset, which we labeled for ages, gender, and semantic segmentation. Fixed age classes are used as anchors to approximate continuous age transformation. Our framework can predict a full head portrait for ages 0--70 from a single photo, modifying both texture and shape of the head. We demonstrate results on a wide variety of photos and datasets, and show significant improvement over the state of the art.

In-Situ CAD Capture
We present an interactive system to capture CAD-like 3D models of indoor scenes, on a mobile device. To overcome sensory and computational limitations of the mobile platform, we employ an in situ, semi-automated approach and harness the user's high-level knowledge of the scene to assist the reconstruction and modeling algorithms. The modeling proceeds in two stages: (1) The user captures the 3D shape and dimensions of the room. (2) The user then uses voice commands and an augmented reality sketching interface to insert objects of interest, such as furniture, artwork, doors and windows. Our system recognizes the sketches and add a corresponding 3D model into the scene at the appropriate location. The key contributions of this work are the design of a multi-modal user interface to effectively capture the user's semantic understanding of the scene and the underlying algorithms that process the input to produce useful reconstructions.

Time-lapse Mining from Internet Photos
We introduce an approach for synthesizing time-lapse videos of popular landmarks from large community photo collections. The approach is completely automated and leverages the vast quantity of photos available online. First, we cluster 86 million photos into landmarks and popular viewpoints. Then, we sort the photos by date and warp each photo onto a common viewpoint. Finally, we stabilize the appearance of the sequence to compensate for lighting effects and minimize flicker. Our resulting time-lapses show diverse changes in the world's most popular sites, like glaciers shrinking, skyscrapers being constructed, and waterfalls changing course.

Deep Classifiers from Image Tags in the Wild
This paper proposes direct learning of image classification from image tags in the wild, without filtering. Each wild tag is supplied by the user who shared the image online. Enormous numbers of these tags are freely available, and they give insight about the image categories important to users and to image classification. Our main contribution is an analysis of the Flickr 100 Million Image dataset, including several useful observations about the statistics of these tags. We introduce a large-scale robust classification algorithm, in order to handle the inherent noise in these tags, and a calibration procedure to better predict objective annotations. We show that freely available, wild tags can obtain similar or superior results to large databases of costly manual annotations.

DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time
We present the first dense SLAM system capable of reconstructing non-rigidly deforming scenes in real-time, by fusing together RGBD scans captured from commodity sensors. Our DynamicFusion approach reconstructs scene geometry whilst simultaneously estimating a dense volumetric 6D motion field that warps the estimated geometry into a live frame. Like KinectFusion, our system produces increasingly denoised, detailed, and complete reconstructions as more measurements are fused, and displays the updated model in real time. Because we do not require a template or other prior scene model, the approach is applicable to a wide range of moving objects and scenes.

VisKE: Visual Knowledge Extraction and Question Answering by Visual Verification of Relation Phrases
How can we know whether a statement about our world is valid. For example, given a relationship between a pair of entities e.g., ‘eat(horse, hay)’, how can we know whether this relationship is true or false in general. Gathering such knowledge about entities and their relationships is one of the fundamental challenges in knowledge extraction. Most previous works on knowledge extraction have focused purely on text-driven reasoning for verifying relation phrases. In this work, we introduce the problem of visual verification of relation phrases and developed a Visual Knowledge Extraction system called VisKE. Given a verb-based relation phrase between common nouns, our approach assess its validity by jointly analyzing over text and images and reasoning about the spatial consistency of the relative configurations of the entities and the relation involved. Our approach involves no explicit human supervision thereby enabling large-scale analysis. Using our approach, we have already verified over 12000 relation phrases. Our approach has been used to not only enrich existing textual knowledge bases by improving their recall, but also augment open-domain question-answer reasoning.

LEVAN: Learning EVerything about ANything
Recognition is graduating from labs to real-world applications. While it is encouraging to see its potential being tapped, it brings forth a fundamental challenge to the vision researcher: scalability. How can we learn a model for any concept that exhaustively covers all its appearance variations, while requiring minimal or no human supervision for compiling the vocabulary of visual variance, gathering the training images and annotations, and learning the models?
In this work, we introduce a fully-automated approach for learning extensive models for a wide range of variations (e.g. actions, interactions, attributes and beyond) within any concept. Our approach leverages vast resources of online books to discover the vocabulary of variance, and intertwines the data collection and modeling steps to alleviate the need for explicit human supervision in training the models. Our approach organizes the visual knowledge about a concept in a convenient and useful way, enabling a variety of applications across vision and NLP. Our online system has been queried by users to learn models for several interesting concepts including, breakfast, Gandhi, beautiful, etc. To date, our system has models available for over 50,000 variations within 150 concepts, and has annotated more than 10 million images with bounding boxes.

Total Moving Face Reconstruction
We present an approach that takes a single video of a person's face and reconstructs a high detail 3D shape for each video frame. We target videos taken under uncontrolled and uncalibrated imaging conditions, such as youtube videos of celebrities. In the heart of this work is a new dense 3D flow estimation method coupled with shape from shading. Unlike related works we do not assume availability of a blend shape model, nor require the person to participate in a training/capturing process. Instead we leverage the large amounts of photos that are available per individual in personal or internet photo collections. We show results for a variety of video sequences that include various lighting conditions, head poses, and facial expressions.
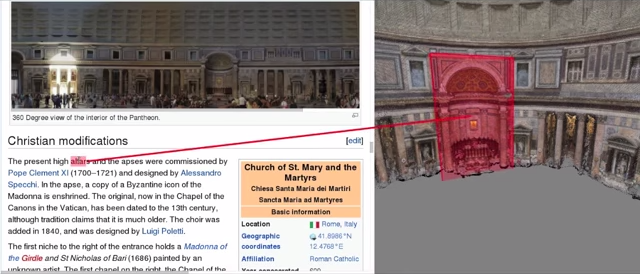
3D Wikipedia: Using Online Text to Automatically Label and Navigate Reconstructed Geometry
We introduce an approach for analyzing Wikipedia and other text, together with online photos, to produce annotated 3D models of famous tourist sites. The approach is completely automated, and leverages online text and photo co-occurrences via Google Image Search. It enables a number of new interactions, which we demonstrate in a new 3D visualization tool. Text can be selected to move the camera to the corresponding objects, 3D bounding boxes provide anchors back to the text describing them, and the overall narrative of the text provides a temporal guide for automatically flying through the scene to visualize the world as you read about it. We show compelling results on several major tourist sites.
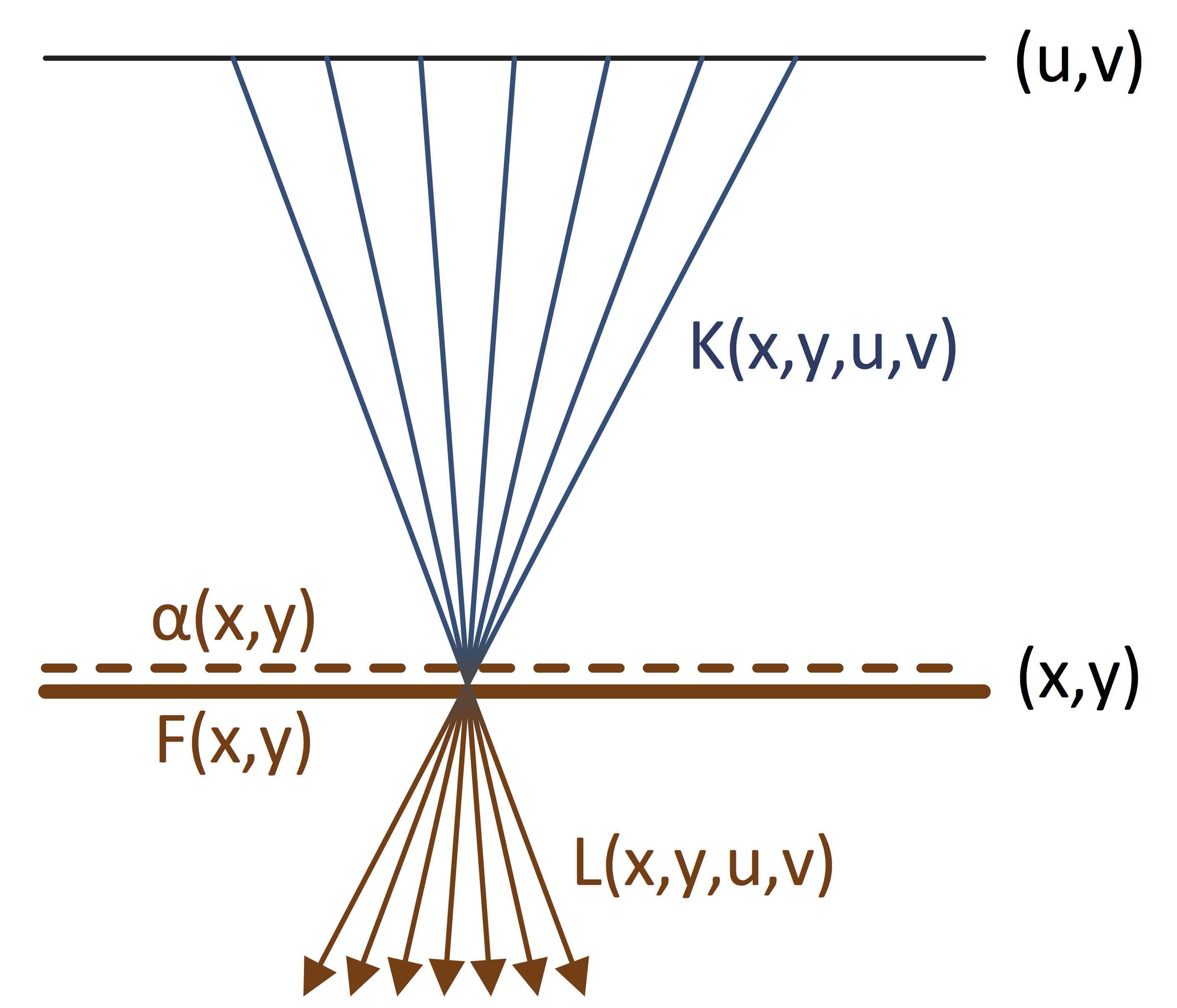
Light Field Layer Mapping
In this paper, we use matting to separate foreground layers from light fields captured with a plenoptic camera. We represent the input 4D light field as a 4D background light field, plus a 2D spatially varying foreground color layer with alpha. Our method can be used to both pull a foreground matte and estimate an occluded background light field. Our method assumes that the foreground layer is thin and fronto-parallel, and is composed of a limited set of colors that are distinct from the background layer colors. Our method works well for thin, translucent, and blurred foreground occluders. Our representation can be used to render the light field from novel views, handling disocclusions while avoiding common artifacts.

Illumination-Aware Age Progression
We present an approach that takes a single photograph of a child as input and automatically produces a series of age-progressed outputs between 1 and 80 years of age, accounting for pose, expression, and illumination. Leveraging thousands of photos of children and adults at many ages from the Internet, we first show how to compute average image subspaces that are pixel-to-pixel aligned and model variable lighting. These averages depict a prototype man and woman aging from 0 to 80, under any desired illumination, and capture the differences in shape and texture between ages. Applying these differences to a new photo yields an age progressed result. Contributions include relightable age subspaces, a novel technique for subspace-to-subspace alignment, and the most extensive evaluation of age progression techniques in the literature.
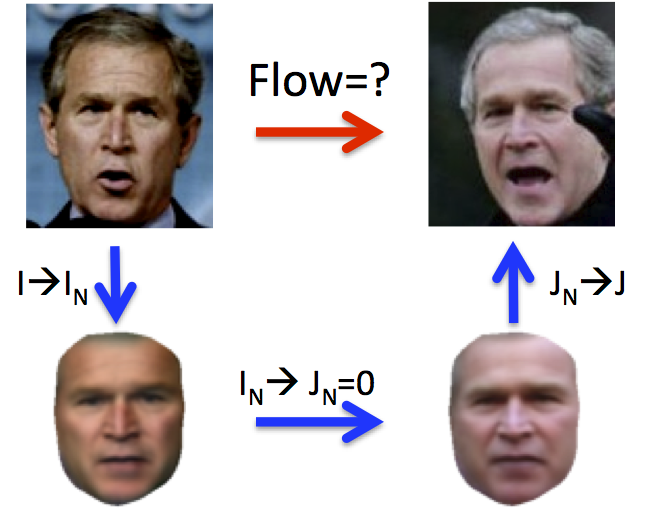
Collection Flow
Computing optical flow between any pair of Internet face photos is challenging for most current state of the art flow estimation methods due to differences in illumination, pose, and geometry. We show that flow estimation can be dramatically improved by leveraging a large photo collection of the same (or similar) object. In particular, consider the case of photos of a celebrity from Google Image Search. Any two such photos may have different facial expression, lighting and face orientation. The key idea is that instead of computing flow directly between the input pair (I,J), we compute versions of the images (I',J') in which facial expressions and pose are normalized while lighting is preserved. This is achieved by iteratively projecting each photo onto an appearance subspace formed from the full photo collection. The desired flow is obtained through concatenation of flows (I-->I') (J'-->J). Our approach can be used with any two-frame optical flow algorithm, and significantly boosts the performance of the algorithm by providing invariance to lighting and shape changes.
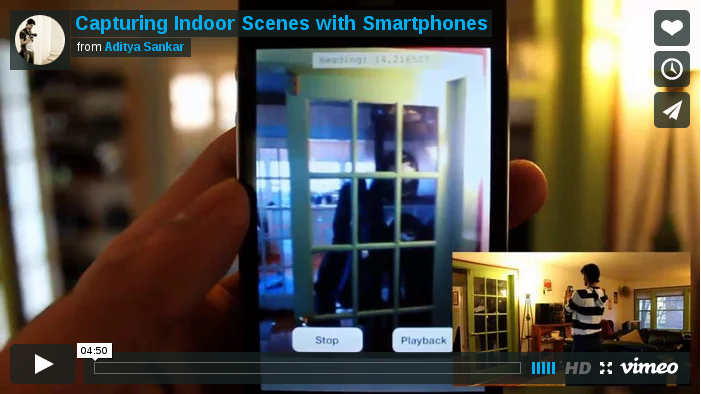
Capturing Indoor Scenes with Smartphones
We present a novel smartphone application designed to easily capture, visualize and reconstruct homes, offices and other indoor scenes. Our application leverages data from smartphone sensors such as the camera, accelerometer, gyroscope and magnetometer to help model the indoor scene. The output of the system is two-fold; first, an interactive visual tour of the scene is generated in real time that allows the user to explore each room and transition between connected rooms. Second, with some basic interactive photogrammetric modeling the system generates a 2D floor plan and accompanying 3D model of the scene, under a Manhattan-world assumption. The approach does not require any specialized equipment or training and is able to produce accurate floor plans.