We introduce Linearly Constrained Diffusion Implicit Models (CDIM), a fast and accurate approach to solving noisy linear inverse problems using diffusion models. Traditional diffusion-based inverse methods rely on numerous projection steps to enforce measurement consistency in addition to unconditional denoising steps. CDIM achieves a 10–50x reduction in projection steps by dynamically adjusting the number and size of projection steps to align a residual measurement energy with its theoretical distribution under the forward diffusion process. This adaptive alignment preserves measurement consistency while substantially accelerating constrained inference. For noise-free linear inverse problems, CDIM exactly satisfies the measurement constraints with few projection steps,
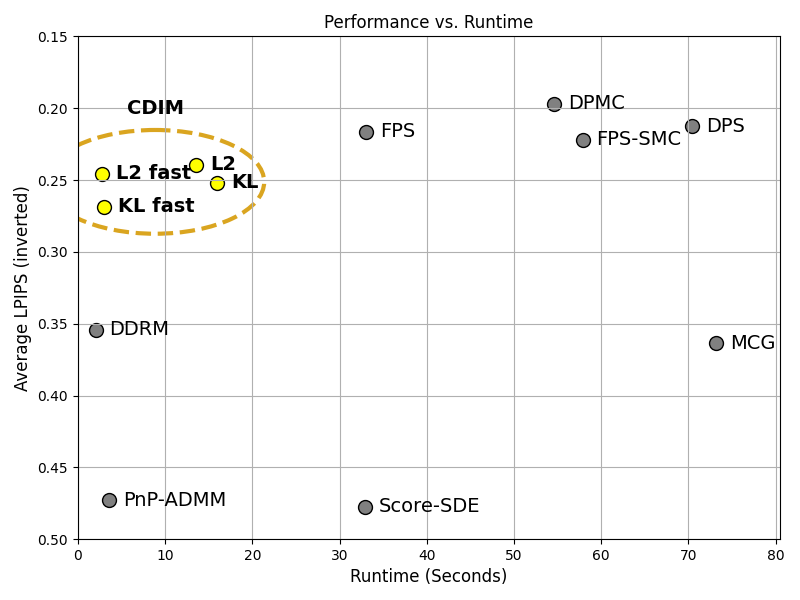
We plot the strength of various methods against the runtime. You can see that our methods (circled in the top left) have very strong performance while requiring a fraction of the runtime of existing methods.
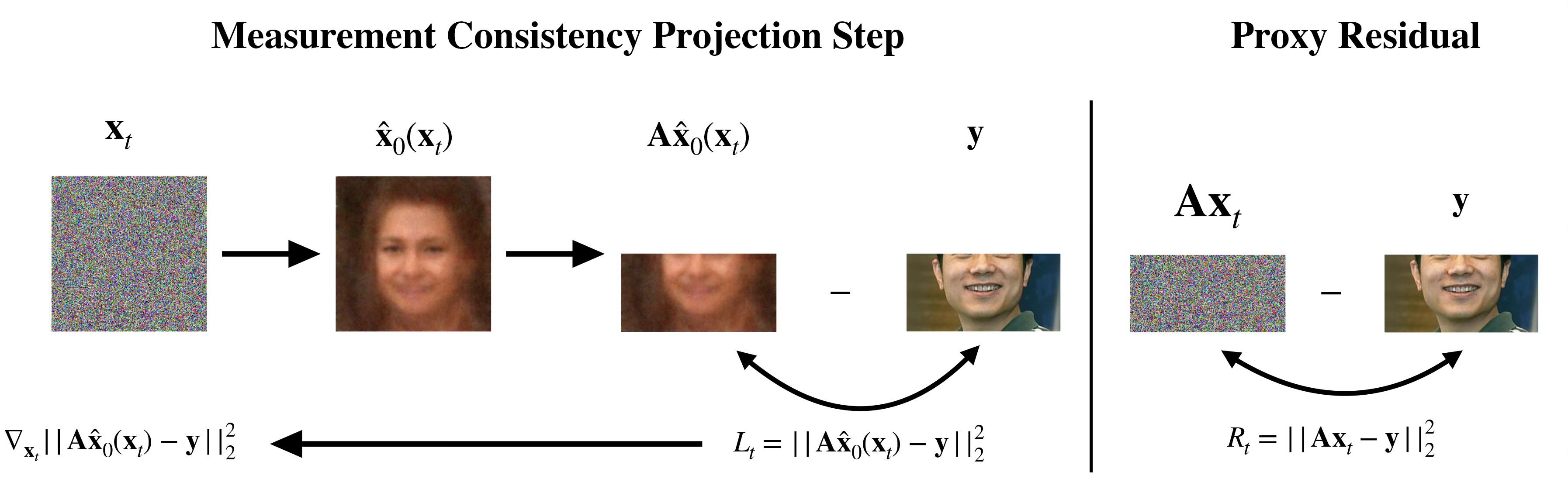
We show an example of the method on a 50% inpainting task where we only observe the bottom half of an image. We alternate unconditional diffusion steps with projection steps on our measurement error $\nabla_{\mathbf{x}_t} \;\|\mathbf{A}\mathbf{\hat{x}}_0(\mathbf{x}_t) - \mathbf{y}\|^2$ (left panel). Our key idea is to use the proxy residual $R_t = \|\mathbf{A}\mathbf{x}_t - \mathbf{y}\|^2$ (right panel), which has analytical chi-squared distribution under the forward noising process, to choose the number and size of projection steps. The full algorithm is written below.


We use CDIM to inpaint a sparse point cloud projection. We take 10 images from the Grand Budapest Hotel movie and use Colmap to create a point cloud. This point cloud when projected from a novel angle is very sparse (left image). We can use CDIM to fill it in (right image).
{vjayaram, seitz, kemelmi}@cs.washington.edu
The authors thank the labmates from UW GRAIL Lab. This work was supported by the UW Reality Lab, Facebook, Google, Lenovo, and Amazon.
