Shu Liang, Linda G. Shapiro, Ira Kemelmacher-Shlizerman
Contact: { liangshu , shapiro , kemelmi } @ cs.washington.edu
Paper
Shu Liang, Linda G. Shapiro, Ira Kemelmacher-Shlizerman. European Conference on Computer Vision, Oct, 2016.
Bibtex
@inproceedings{liang2016head,
title={Head Reconstruction from Internet Photos},
author={Liang, Shu and Shapiro, Linda G and Kemelmacher-Shlizerman,
Ira},
booktitle={European Conference on Computer Vision},
pages={360--374},
year={2016},
organization={Springer}
}
Dataset
Abstract
3D face reconstruction from Internet photos has recently produced exciting results. A person's face, e.g., Tom Hanks, can be modeled and animated in 3D from a completely uncalibrated photo collection. Most methods, however, focus solely on face area and mask out the rest of the head. This paper proposes that head modeling from the Internet is a problem we can solve. We target reconstruction of the rough shape of the head. Our method is to gradually "grow" the head mesh starting from the frontal face and extending to the rest of views using photometric stereo constraints. We call our method boundary-value growing algorithm. Results on photos of celebrities downloaded from the Internet are presented.
Pipeline
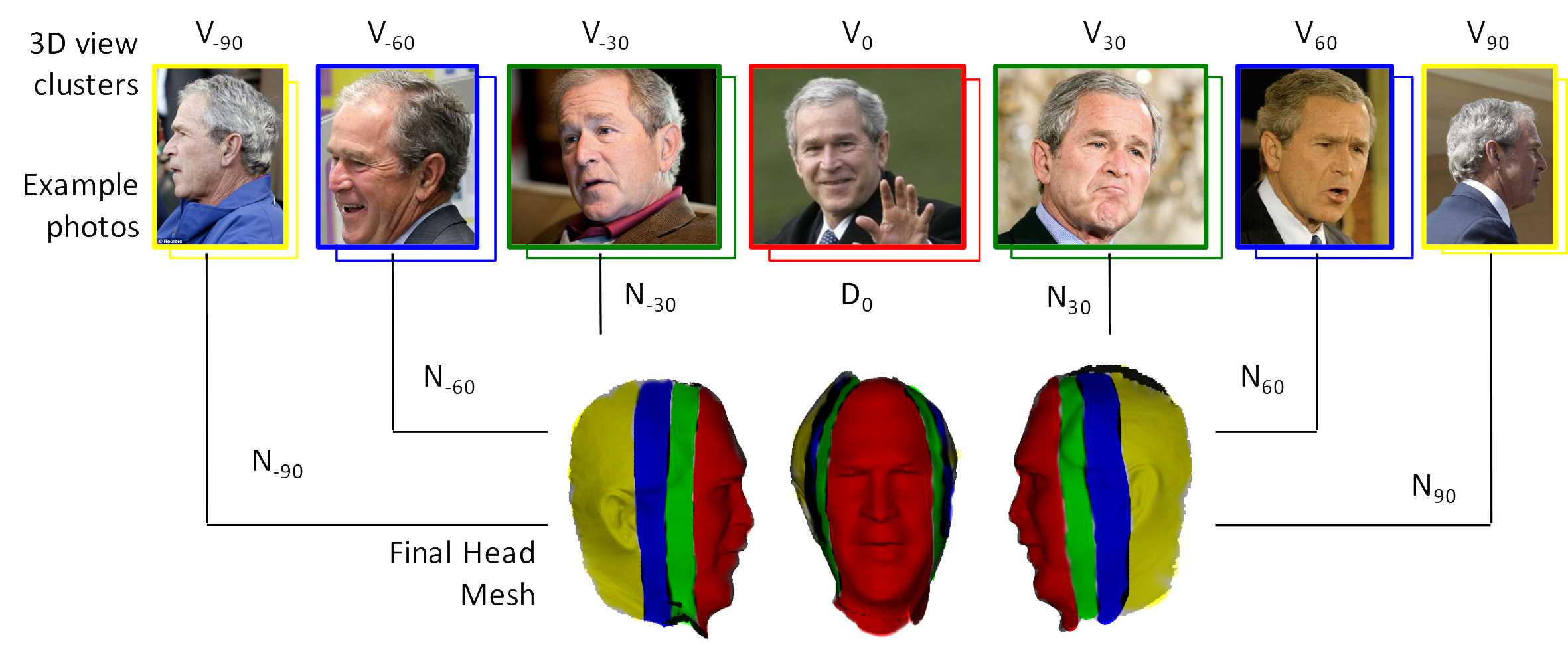
We denote the set of photos in a view cluster as Vi. Photos in the same view cluster have approximately the same 3D pose and azimuth angle. Specifically, we divided the photos into 7 clusters with azimuths: i = 0;-30; 30;-60; 60;-90; 90. The figure below shows the averages of each cluster after rigid alignment using fiducial points (1st row) and after subsequent alignment using the Collection Flow method (2nd row), which calculates optical ow for each cluster photo to the cluster average. A key observation is that each view cluster has one particularly well reconstructed head area, e.g., the ears in views 90 and -90 are sharp while blurry in other views. Since our goal is to create a full head mesh, our algorithm will combine the optimal partsfrom each view into a single model.

Result

Acknowledgements
We thank Samsung, Google, and NSF/Intel grant #1538613 for funding this research.