The Queue Method: Handling Delay, Heuristics, Prior Data, and Evaluation in
Bandits
Abstract
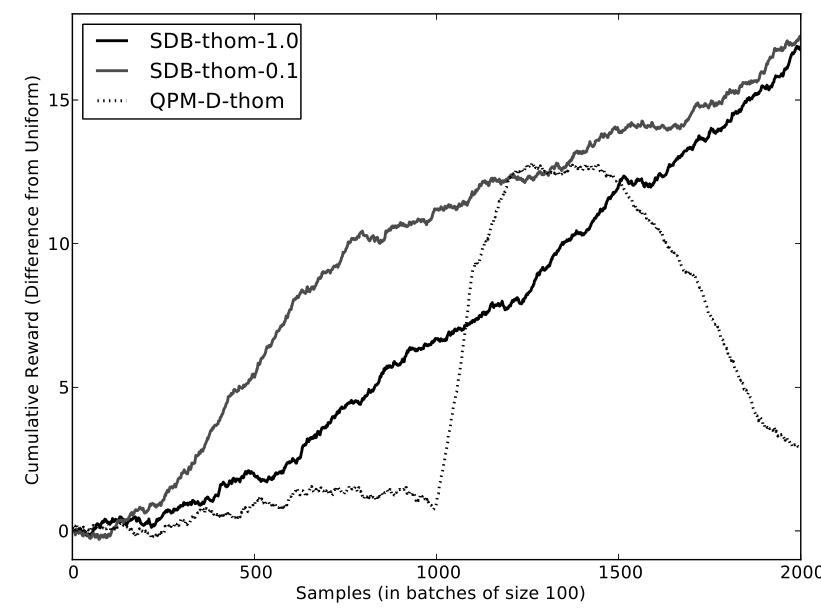
Current algorithms for the standard multi-armed bandit problem have good empirical performance and optimal regret bounds. However, real-world problems often differ from the standard formulation in several ways. First, feedback may be delayed instead of arriving immediately. Second, the real world often contains structure which suggests heuristics, which we wish to incorporate while retaining strong theoretical guarantees. Third, we may wish to make use of an arbitrary prior dataset without negatively impacting performance. Fourth, we may wish to efficiently evaluate algorithms using a previously collected dataset. Surprisingly, these seemingly-disparate problems can be addressed using algorithms inspired by a recently-developed queueing technique. We present the Stochastic Delayed Bandits (SDB) algorithm as a solution to these four problems, which takes black-box bandit algorithms (including heuristic approaches) as input while achieving good theoretical guarantees. We present empirical results from both synthetic simulations and real-world data drawn from an educational game. Our results show that SDB outperforms state-of-the-art approaches to handling delay, heuristics, prior data, and evaluation.
Authors
Resources