Offline Evaluation of Online Reinforcement Learning Algorithms
Abstract
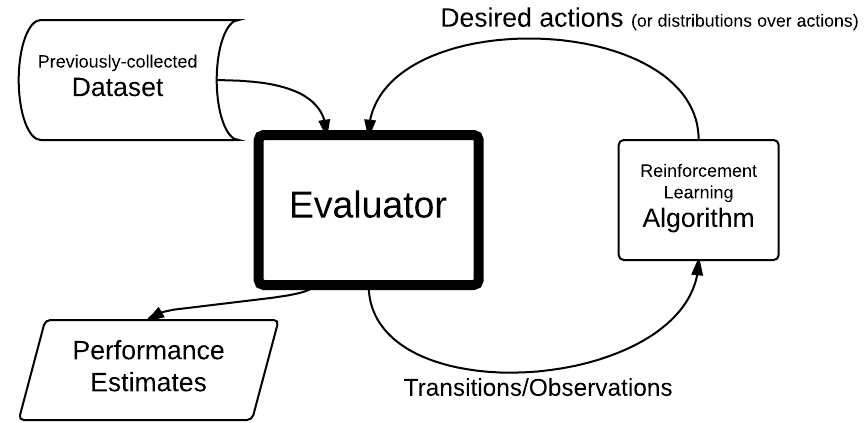
In many real-world reinforcement learning problems, we have access to an existing dataset and would like to use it to evaluate various learning approaches. Typically, one would prefer not to deploy a fixed policy, but rather an algorithm that learns to improve its behavior as it gains more experience. Therefore, we seek to evaluate how a proposed algorithm learns in our environment, meaning we need to evaluate how an algorithm would have gathered experience if it were run online. In this work, we develop three new evaluation approaches which guarantee that, given some history, algorithms are fed samples from the distribution that they would have encountered if they were run online. Additionally, we are the first to propose an approach that is provably unbiased given finite data, eliminating bias due to the length of the evaluation. Finally, we compare the sample-efficiency of these approaches on multiple datasets, including one from a real-world deployment of an educational game.
Authors
Resources