Abstract
Head Related Transfer Functions (HRTFs) play a crucial role in creating immersive spatial audio experiences. However, HRTFs differ signifcantly from person to person, and traditional methods for estimating personalized HRTFs are expensive, time-consuming, and require specialized equipment. We imagine a world where your personalized HRTF can be determined by capturing data through earbuds in everyday environments. In this paper, we propose a novel approach for deriving personalized HRTFs that only relies on in-the-wild binaural recordings and head tracking data. By analyzing how sounds change as the user rotates their head through diferent environments with diferent noise sources, we can accurately estimate their personalized HRTF. Our results show that our predicted HRTFs closely match ground-truth HRTFs measured in an anechoic chamber. Furthermore, listening studies demonstrate that our personalized HRTFs signifcantly improve sound localization and reduce front-back confusion in virtual environments. Our approach ofers an efcient and accessible method for deriving personalized HRTFs and has the potential to greatly improve spatial audio experiences.
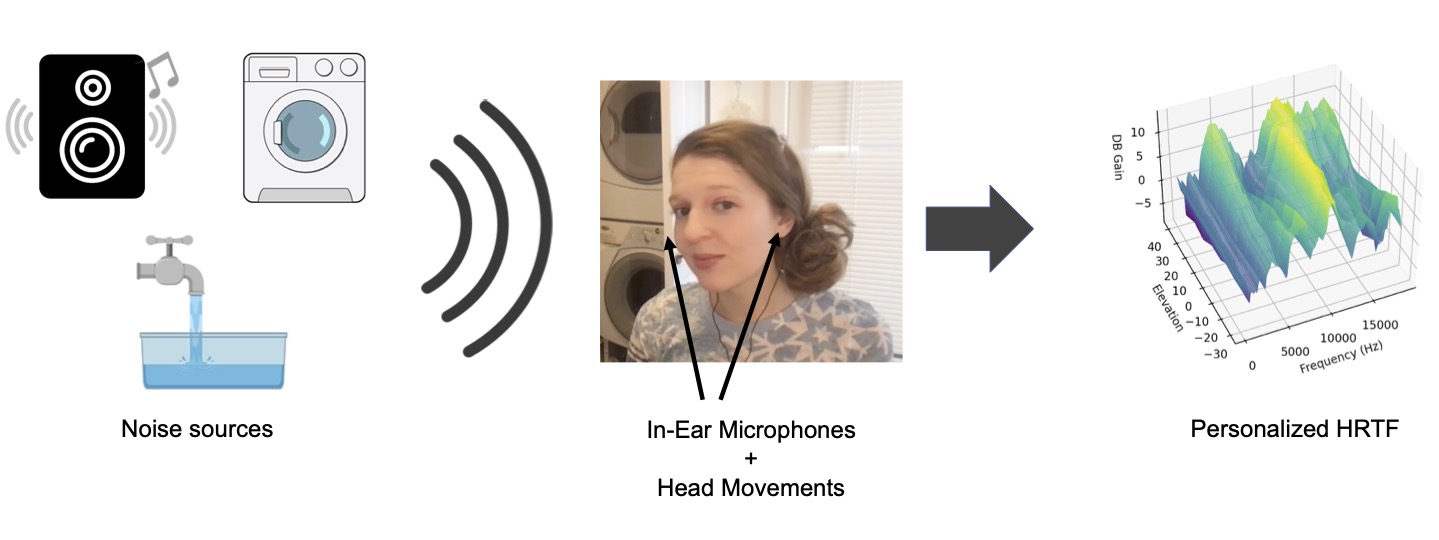
Method
An overview of our method. We use binaural recordings of in-the-wild sounds to predict the fltering from the HRTF at each time step. We then use the head tracking data to map this predicted fltering to the user’s location dependent HRTF.
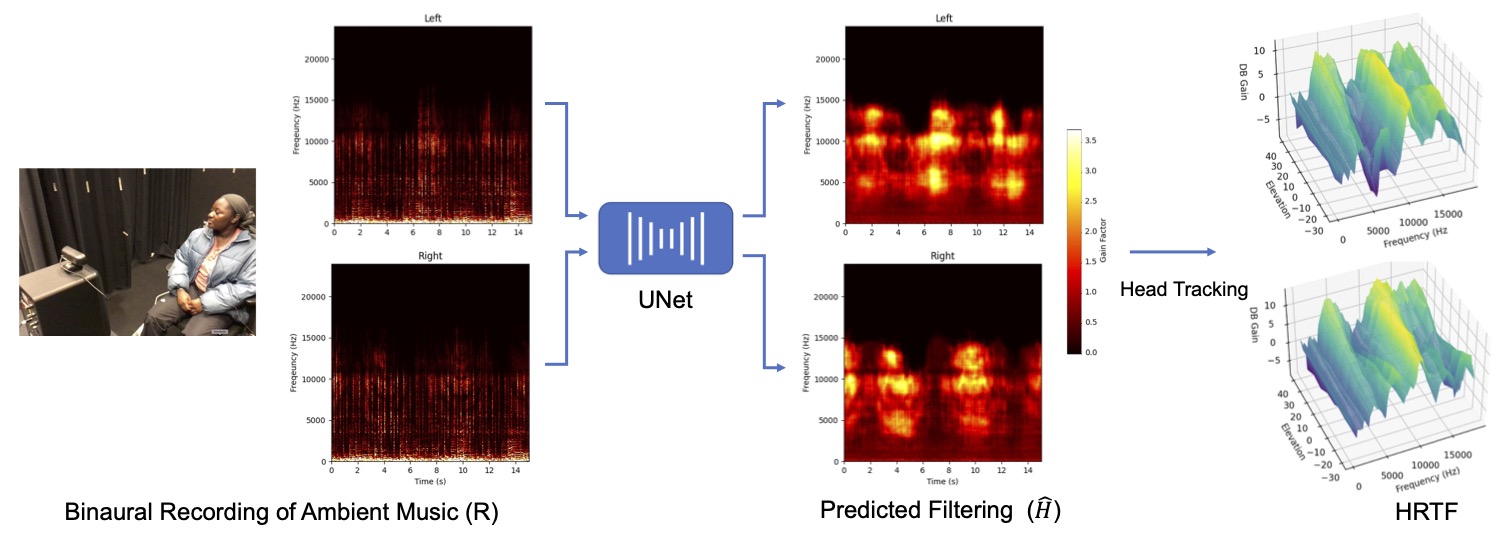
User Studies
Comparison with Ground Truth HRTF
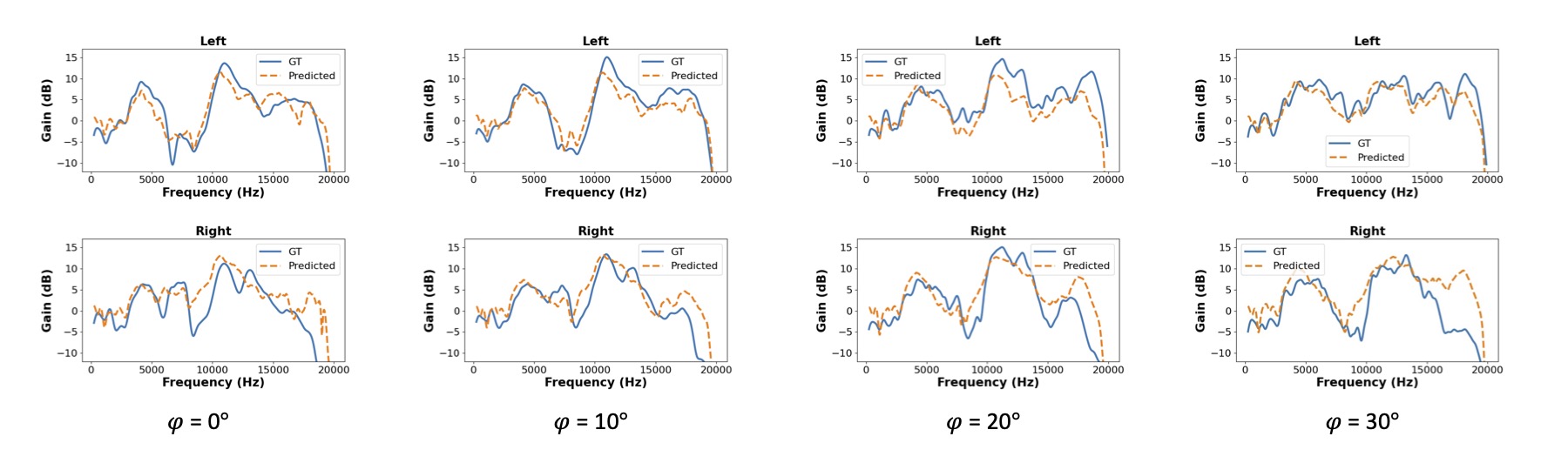
We plot the ground-truth HRTF and predicted HRTF for a given test subject for phi = 0° and 4 elevations. The HRTF that we create for the user closely matches the ground truth, even though the magnitude of some notches and peaks may not be exactly correct
Front Back Confusion
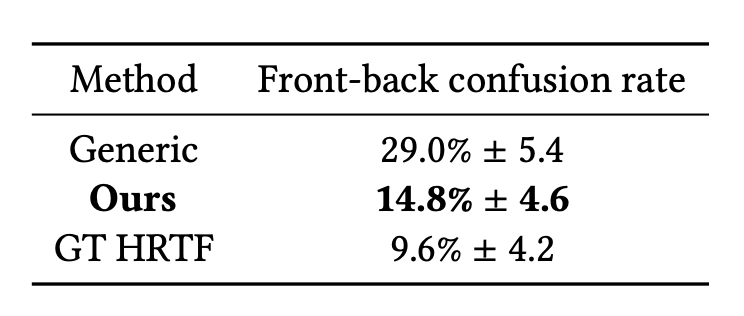
Front-back confusion with rendered sounds. We report the percent of times the listeners made an error, along with the frst standard deviation
Localization of Virtual Sounds
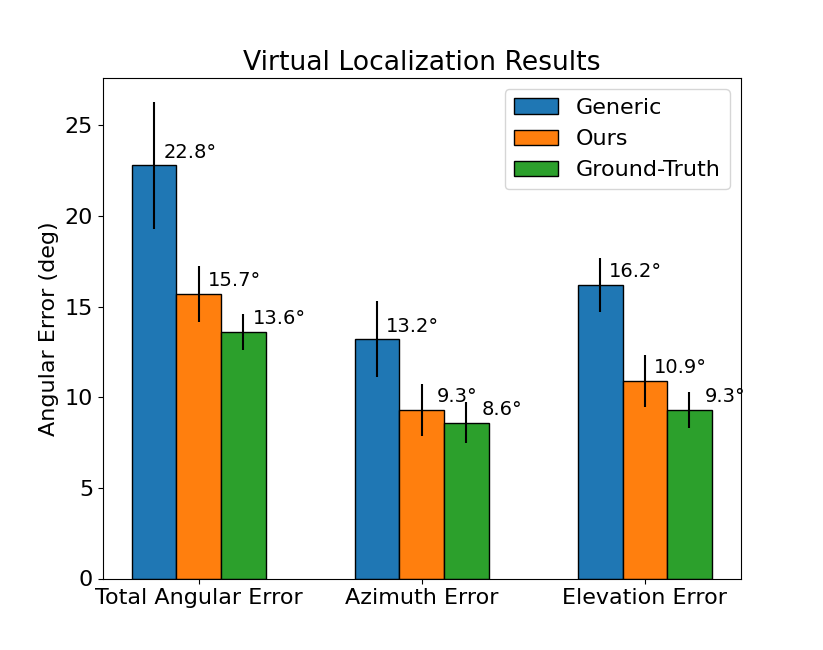
Localization results for the virtual auditory display experiment. Results are reported for 3 diferent experiments: a generic HRTF, the HRTF predicted using our method, and the ground-truth anechoic HRTF described in Section 4.2. For each experiment, we frst show the total angle diference between the source and prediction. We then show the pre- diction error broken down by azimuth and elevation error. Results are averaged over all subjects and trials. Error bars shown are the frst standard error of the mean
Source code
Training code and inference code coming soon
Citation
Contact and Info
UW GRAIL, UW Reality Lab, University of Washington
{vjayaram, seitz, kemelmi}@cs.washington.edu
Acknowledgements
The authors thank the labmates from UW GRAIL Lab. This work was supported by the UW Reality Lab, Facebook, Google, Futurewei, and Amazon.