Video to Fully Automatic 3D Hair Model
Abstract
Imagine taking a selfie video with your mobile phone and getting as
output a 3D model of your head (face and 3D hair strands) that can be
later used in VR, AR, and any other domain. State of the art hair
reconstruction methods allow either a single photo (thus compromising 3D
quality), or multiple views but require manual user interaction (manual
hair segmentation and capture of fixed camera views that span full 360
angles). In this paper, we present a system that can create a
reconstruction from any video (even a selfie video), completely
automatically, and we don't require specific views since taking your -90
degree, 90 degree, and full back views is not feasible in a selfie
capture.
In the core of our system, in addition to the automatization components,
hair strands are estimated and deformed in 3D (rather than 2D as in
state of the art) thus enabling superior results. We present
qualitative, quantitative, and Mechanical Turk human studies that
support the proposed system, and show results on diverse variety of
videos (8 different celebrity videos, 9 selfie mobile videos, spanning
age, gender, hair length, type, and styling).
Results

Pipeline
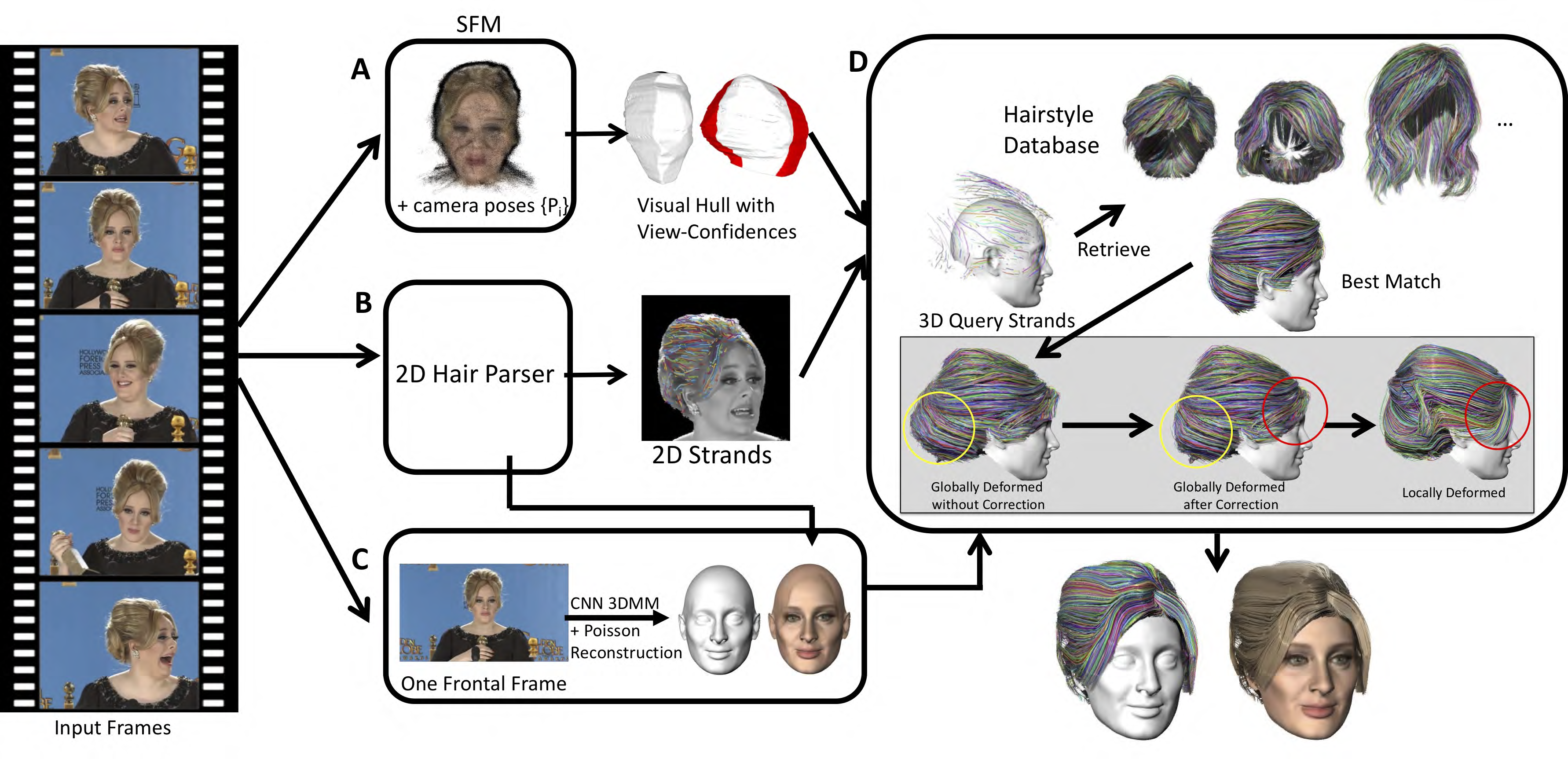
This figure provides an overview of our method and the key components. The input to the algorithm is a video sequence of a person talking and moving naturally, as in a TV interview. There are four algorithmic components (correspond to the labeling of boxes):(A) video frames are used to create a structure-from-motion model, estimate camera poses as well as per-frame depth, and compute a rough visual hull of the person with view-confidences, (B) two models are trained: one for hair segmentation, and another for hair direction; given those models, 2D hair strands are estimated and hair segmentation results are transferred to the visual hull to define the hair region, (C) the masks from the previous stage are used to separate the hair from the face and run the morphable model (3DMM) to estimate the face shape and later create the texture of the full head.
(D) is a key contribution in which first depth maps and 2D hair strands are combined to create 3D strands, and then 3D strands are used to query a database of hair styles. The match is deformed according to the visual hull, then corrected based on the region of confidence of the visual hull. Finally, it is deformed on the local strand level to fit the input strands. Texture is estimated from input frames to create the final hair model. The full head shape is a combination of the face model and the hair strands.
Paper
Paper pdf, to appear in Siggraph Asia 2018!
@ARTICLE{2018arXiv180904765L,
author = {{Liang}, S. and {Huang}, X. and {Meng}, X. and {Chen}, K. and
{Shapiro}, L.~G. and {Kemelmacher-Shlizerman}, I.},
title = "{Video to Fully Automatic 3D Hair Model}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprint = {1809.04765},
primaryClass = "cs.CV",
keywords = {Computer Science - Computer Vision and Pattern Recognition, Computer Science - Graphics},
year = 2018,
month = sep,
adsurl = {http://adsabs.harvard.edu/abs/2018arXiv180904765L},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}