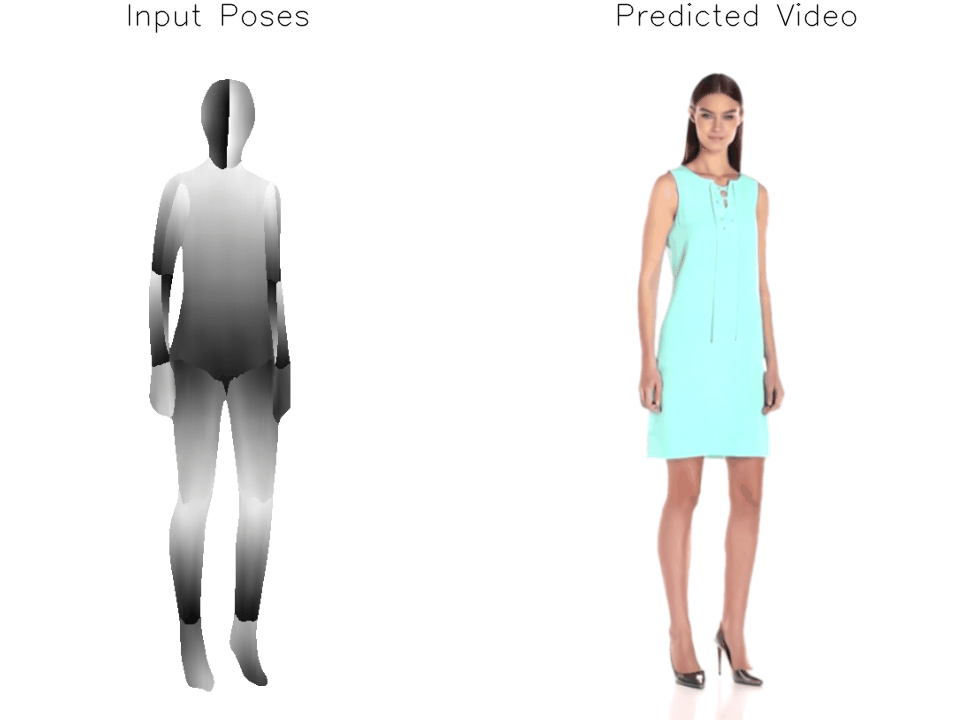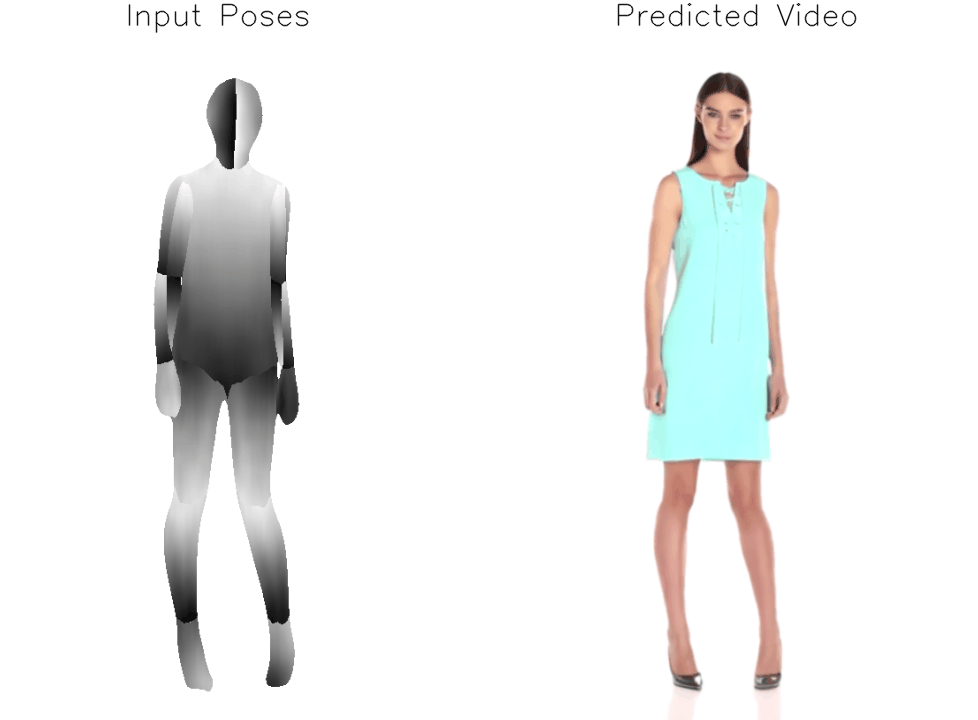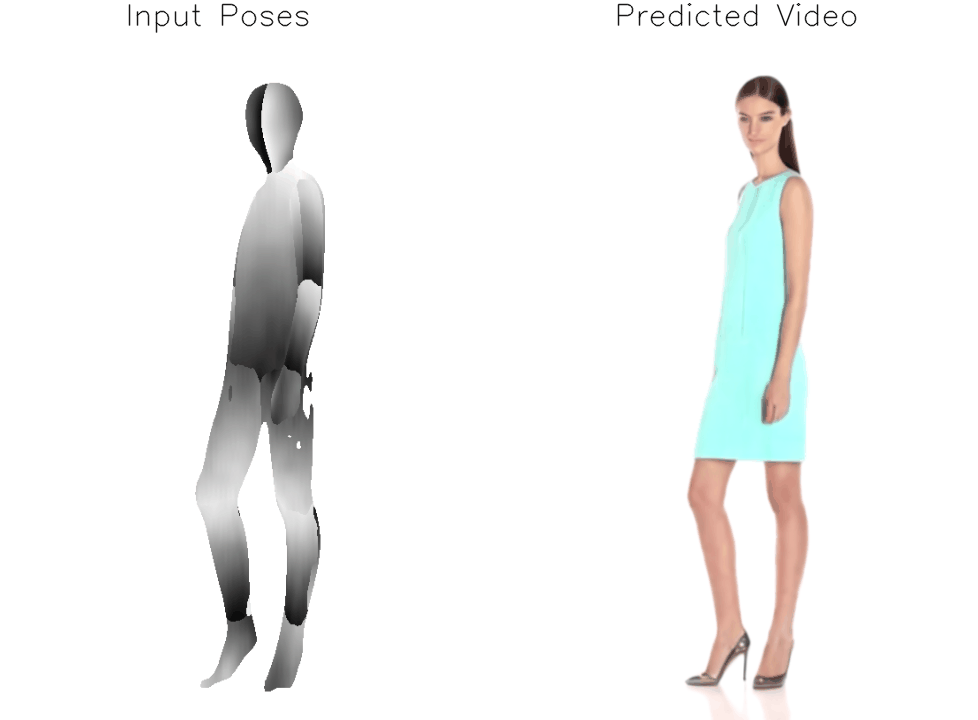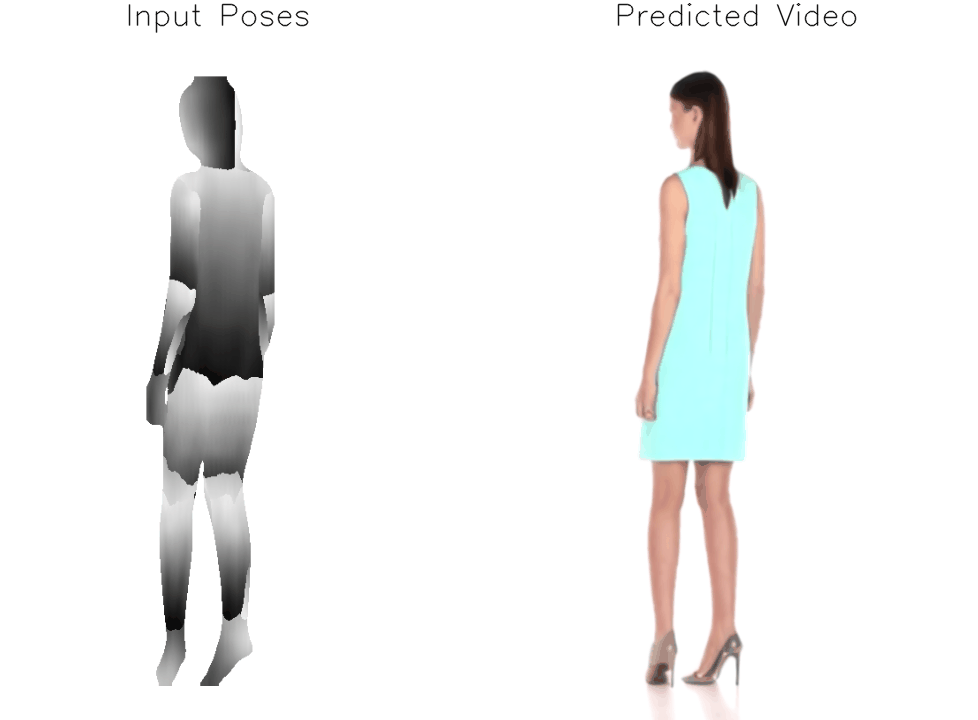
Architecture

a) We modify the original Stable Diffusion architecture in order to enable image and pose conditioning. First, we replace the CLIP text encoder with a dual CLIP-VAE image encoder. Then, we concatenate the target pose representation, consisting of {pi-1, pi-1, pi, pi+1, pi+2} where pi is the target pose, to the input noise. During training, we finetune the denoising UNet and our Adapter module on the full dataset and further perform subject-specific finetuning of the UNet, Adapter, and VAE Decoder on a single input image. b) We implement an adapter module to jointly model and reshape the concatenated pretrained CLIP and VAE embeddings for conditioning the UNet on the input frame.