| PREVIOUS | NEXT |
| INDEX | |
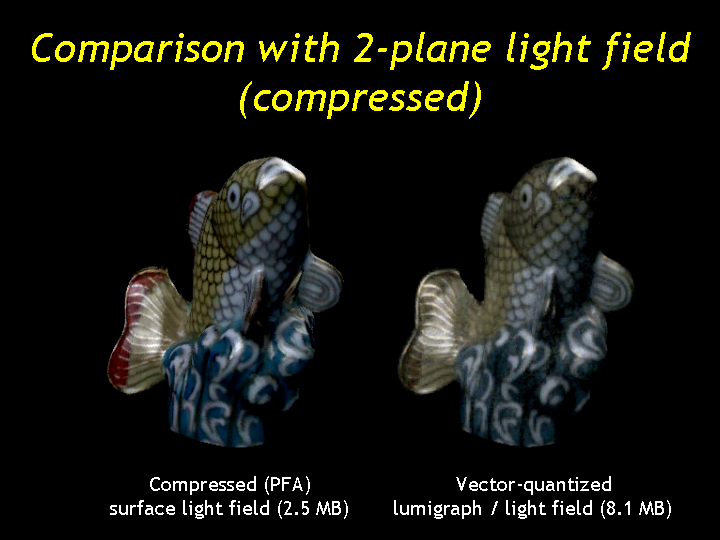
If we compress the light field using the VQ strategy of Levoy and Hanrahan (SIGGRAPH 1996) it shows considerable more artifacts than the compressed SLF, despite being 3 times larger (MOVIE). The VQ fails, in part, because the light field resolution is rather low and there is, therefore, less coherence. (Of course increasing the resolution will just increase the size, so that's not an easy solution.)