Select the slide images to see a larger version. The
talk can also be navigated from within the enlarged slides.
 | | Daniel Wood | University of Washington | | Daniel Azuma | University of Washington | | Ken Aldinger | University of Washington | | Brian Curless | University of Washington | | Tom Duchamp | University of Washington | | David Salesin | University of Washington and Microsoft Research | | Werner Stuetzle | University of Washington | |
 | Howdy. I'll be describing some work my co-authors and I have been doing in the area of 3D photography. I will define this as capturing the shape and / or the color of objects in a form that can be manipulated in a 3D way. We're particular interested in shiny objects. The changing appearance with viewpoint makes these interesting and challenging objects. And, I believe, and I think that you will agree, a world without shiny objects would be a very dull place. laughter We have derived our goals by looking at what people do with standard 2D photography and then asking how we can extend that to 3D. So obviously viewing / rendering is important (MOVIE), but we'd also like to be able to process and edit 3D photographs (crop them, warp them, etc.). In our work we have achieved the basic goal of rendering and we've made some progress on editing. Our problem then becomes: given inputs (photos and geometry) estimate some model that we can render and edit in 3D. I'll start by briefly describing some related work that has tackled the rendering side of this problem. |
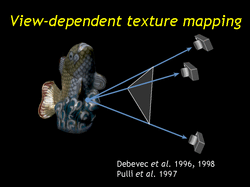 | View-dependent texture mapping also takes as input photos and geometry. |
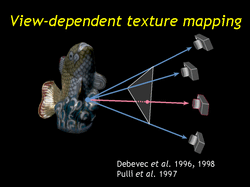 | Given a novel camera position we can synthesize an image from that camera's perspective by projecting the input photographs onto the geometry and interpolating between the resulting images--primarily based on how close they are to the new viewpoint. |
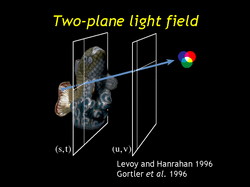 | If we have low resolution geometry or a highly specular object then we will need more photographs to produce high quality synthetic images. If we have many photographs it will be beneficial to arrange them in a regular pattern to make rendering more efficient. The light field (or lumigraph) uses photographs placed on a regular grid. If the resolution is high enough then synthetic images can be reconstructed without using any geometry at all, but the Lumigraph paper (Gortler et al) described how to use geoemtry to increase the quality of the rendering. |
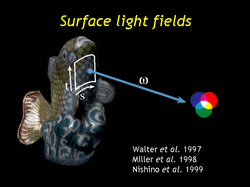 | Both of these techniques keep image and geometric data separate. A surface light field (SLF), on the other hand, binds them tightly together. A SLF requires parameterized geometry and then encodes for every point on the surface and every direction (omega) the radiance leaving that point in that direction. Walter et al and Miller et al have used these to store pre-computed global illumination solutions. Nishino et al have done some related work in the 3D photograph realm. Among other differences with our work, the Nishino et al approach requires a particular configuration of input images and does not address interactive rendering or editing. (See the paper for a more in-depth analysis of the related work.) |
 | An equivalent way to view a SLF is as a function from the surface to lumispheres, where a lumisphere is a function from direction to color that represents the radiance leaving a point in all directions. This is the viewpoint that we take in our work. All of our techniques will make use of the fact that the lumisphere encodes a whole sphere of light and not just an outward facing hemisphere. We use lumispheres that are piecewise-linear with respect to a tesselation of the sphere which is described in the paper. |
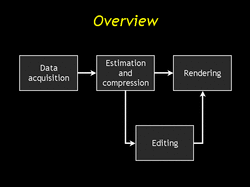 | This talk will follow the chronological order of our process. First we acquire our data and do some preliminary processing. Then we estimate a SLF. Then we can render it. Finally we describe some editing operations. |
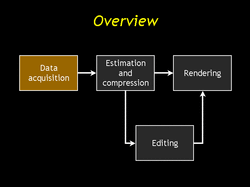 | First we have to get some data to work with. The specifics of our data acquisition strategy are not essential to our work, but I want to present a full end to end approach, therefore I'll discuss them but only briefly. |
 | We use a laser range scanner and standard techniques like those described in Curless and Levoy in SIGGRAPH 1996 to produce a geometric model. We're focusing on shiny objects which can be hard to scan. We coated our examples with a removable powder (Magnaflux Spotcheck SKD-S2 Developer) before scanning. |
 | We also used the Stanford spherical gantry to take photographs of the object from a set of known camera positions using a calibrated camera. Here we can see the camera positions and a few example photographs (MOVIE). |
 | We know the positions of the photographs relative to one another but not relative to the scanned geometry. |
 | Therefore we hand-selected some points on the geometry and for each point we selected a corresponding point in any one of the photographs. Applying iterative closest points to this set of point-ray correspondences registers the geometry to the photographs. |
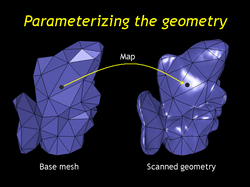 | We use the MAPS technique of Lee et al from SIGGRAPH 1998 to produce a simplified base mesh and a map from it back to the original scanned geometry. This parameterization will be particularly important to our rendering algorithm. |
 | We sample the base mesh by using a standard rectilinear grid on top of each base mesh face with width and height chosen to meet a user-specified sampling rate. |
 | Each sample point is mapped back to the high-resolution geometry and then that point is mapped into the input photographs. For each photo where it is visible we get a direction-color pair (the color is the color of the point as seen from that camera). The collection of these pairs we call a data lumisphere. |
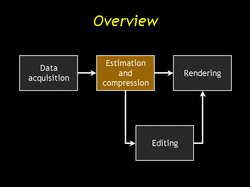 | The estimatino problem, then, is: given data lumispheres for each surface point how do we find a piecewise-linear lumisphere for each surface point. |
 | The first, simplest, technique is to estimate the least-squares best approximating lumisphere for each surface point individually. Because the data lumisphere does not cover the entire sphere we need a roughness penalty to regularize the problem. We define our error functional as the the sum of a distance term which measures how well the lumisphere approximates the data lumisphere and a thin-plate energy term measuring the smoothness of the lumisphere. |
 | This produces high quality results as seen in this comparison of an input photograph and a synthetic rendering. The highlights are slightly dimmer but the features of the original photograph are captured. This quality, however, comes with the cost of a large file size. |
 | Here's another picture of what we've done. We take a lot of data lumispheres and made a whole lot of faired lumispheres. To make the file size smaller we're going to look for a smaller set of lumispheres on the right that can represent all of the data. |
 | Piecewise-linear lumispheres lie in a vector space so we could use standard compression techniques like vector quantization (VQ) or principal compenent analysis (PCA) to represent them using a small set of prototypes. However the faired lumispheres have already gone through a resampling step. In fact they are mostly fiction generated by the regularizing term. |
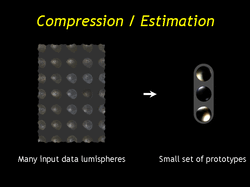 | Instead we want to go directly from the data lumispheres to a samll set of prototypes. We have generalized VQ and PCA to work like this. Before I explain our new algorithms, though, I need to describe two transformations we apply to the data lumispheres to make them more compressible. |
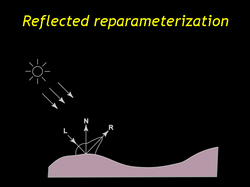 | The first is reflection. Here (on the left) you can see a 2D slice through a lumisphere. |
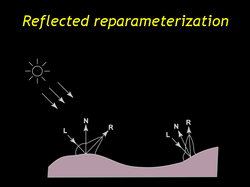 | And here another. Notice that the specular lobes point in different directions, largely because of the different normals. |
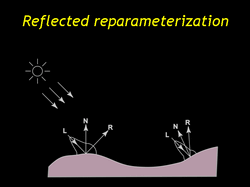 | If we reflect the lumispheres through their normals the specular lobes point in the same approximate direction, back towards the light source. And the reflected lumispheres look much more similar to one another. Both of these representations store the same information. If we keep the normal along with the lumisphere then we can perform the reverse transformation at rendering time. |
 | Here are some faired lumispheres from the fish shown both before and after reflection. Note that the specular highlights are better-aligned afterwards. |
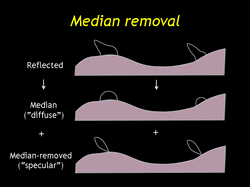 | The second transformation is median-removal, by analogy with mean-removed VQ. We subtract the median value from each data lumisphere. (We use the median rather than the mean because it is robust with respect to outliers and missing data.) If we store the median values uncompressed we can ensure that detailed diffuse texture will be maintained through compression. |
 | Here are the median values for the fish, the residual "specular" values and the summed-result. (MOVIE) |
 | OK, now back to compressed estimation. We call our generalization of vector quantization function quantization. We form a codebook consisting of a small set of codeword lumispheres; then associate each data lumisphere with the best codeword--where best is measured using the same regularized error functional we minimized for pointwise fairing. |
 | We can construct this codebook using a slightly modified algorithm for vector quantization. Begin with a set of data lumispheres. |
 | Construct an optimal codeword by simply aggregating all of the samples in all of the data lumispheres together and then using linear least squares to find the piecewise-linear lumisphere that minimizes the error functional for all of these samples at once. |
 | We can split and perturb this codeword to produce a larger codebook. |
 | If we assign each data lumisphere to the closest codeword in the codebook we form clusters. |
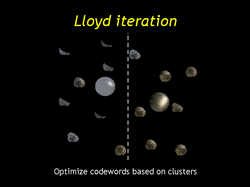 | Then optimize each codeword for only the data lumispheres in it's cluster. |
 | Repeat the cluster-optimize process until convergence. Then split the codebook again. Repeat this outer splitting loop until the codebook is the desired size or quality. |
 | Here is the FQ SLF compared with an input photograph. Despite more than 50:1 compression relative to the piecewise-faired version the fidelity to the input is still good though the highlights are noticeably dimmer. Each codeword / prototype has to represent a number of data lumispheres, so if the highlights in the reflected data lumispheres are not perfectly aligned they will be somewhat blurred / dimmed as you can see here. (I should also note that these file sizes don't include the size of the geometry which is another megabyte or so.) |
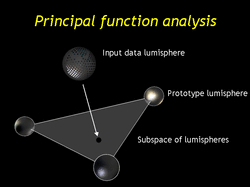 | Our second compression technique is a generalization of PCA we call principal function analysis. Again we find a set of prototypes but instead of picking one to approximate each data lumisphere, we approximate a data lumisphere with a linear combination of the prototypes. |
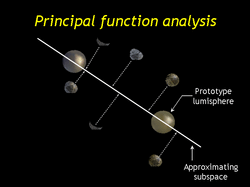 | Here's a side view. The prototypes form a linear subspace of lumisphere space, and the data lumispheres are represented using the member of this subspace which is closest using our same error functional. Standard PCA (eigenanalysis) techniques do not generalize to the principal function analysis situation, so we use conjugate gradients to optimize the prototypes. |
 | To make the optimization more stable we project the inputs onto the convex hull of the prototypes, not the space spanned by them. We also add a small spring energy holding the prototypes together. |
 | At the end of the optimization the prototypes will form a tight approximating simplex to the data. Almost all of the data lumispheres will project to the interior of the simplex. |
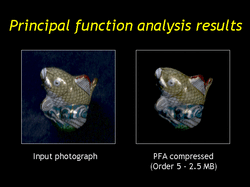 | Again we compare the surface light field with an input photograph, and again the results are attractive but still with slightly dimmer highlights. |
 | We can compare our three estimation techniques (MOVIE). In our experience FQ produces higher fidelity results but has objectionable quantization artifacts. Principal function analysis produces smoother SLFs but with slightly less accuracy. There is not a clear winner--the choice probably depends on the application. |
 | We constructed a 2 plane light field of the same size as our piecewise-linear (uncompressed) surface light field (MOVIE). There were a number of decisions to be made about how to arrange the light field--these are discussed in greater detail in the paper and a tech report. We use the geometry-corrected rendering technique of the Lumigraph paper with the full scanned geometry. These two models are of roughly equal quality: the SLF has sharper surface detail but the lumigraph gets some nice anti-aliasing for free. |
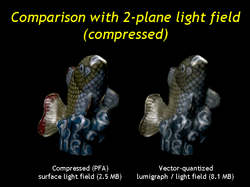 | If we compress the light field using the VQ strategy of Levoy and Hanrahan (SIGGRAPH 1996) it shows considerable more artifacts than the compressed SLF, despite being 3 times larger (MOVIE). The VQ fails, in part, because the light field resolution is rather low and there is, therefore, less coherence. (Of course increasing the resolution will just increase the size, so that's not an easy solution.) |
 | Now that we have estimated surface light fields, I can describe our rendering algorithm. |
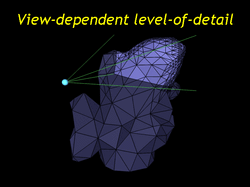 | First we adaptively subdivide the base mesh to provide a good view-dependent appoximation to the input geometry. Our view-dependent level-of-detail algorithm is similar to Hugues Hoppe's view-dependent extension to progressive meshes but operates on meshes with subdivision connectivity. This subdivision connectivity / lazy wavelet formulation makes texture information and texture distortion transparent to work with. |
 | Second, we render the geometry in false color. The RGBA value in each frame buffer pixels encodes the surface location--a base mesh face ID and barycentric coordinates in that face. |
 | Then we can just scan across the frame buffer maintaining a view direction vector and evaluate the surface light field. (Given the surface location we can lookup the appropriate lumisphere and lookup the normal to "unreflect" it. Then we can compute the value of the lumisphere in the view direction.) |
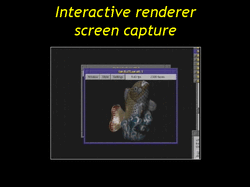 | Here is a screen capture (MOVIE) of our interactive viewer running on a 550 MHz pentium 3 xeon using no 3D graphics hardware. The first model is a pointwise-faired fish, and the second is a PFA elephant. This shows that we can render interactively straight from the compressed representation. |
 | Now I'll briefly describe some editing operations. It's important to note that these editing operations are not physically correct. The paper describes the fairly restrictive conditions under which they would actually be accurate. We violate these conditions, but still get plausible results. |
 | The first operation is lumisphere filtering. We apply a simple bias function to the values in the lumisphere, making the specular lobes taller and narrower. This makes the surface appear glossier. |
 | Here is an animation of the surface becoming more glossy (MOVIE). |
 | Although a lumisphere is not a radiance environment map (REM) the reflected lumispheres are similar to REMs and if we rotate the lumispheres it gives the impression of rotating the environment around the object. |
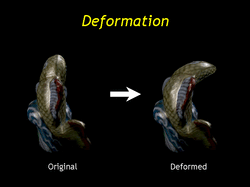 | Again treating the reflected lumispheres as approximate REMs we can perform arbitrary deformations on a SLF and produce plausible renderings of the deformed model. As I noted the restrictions on our editing techniques are described in the paper, but I will point out that neither environment rotation nor deformation deal properly with the diffuse component of the surface color. |
 | Here is an animation of the fish undergoing deformation. |
 | Summary TODO |
 | - Better geometry-to-image registration: the current geometry to image registration is no better than the user input which is a problem. We should use the user input as a starting point to some more general optimization.
- More complex surfaces: In particular we should try out surface light fields on objects with vague surfaces like stuffed animals because these are objects that have been successfully modeled using light field / lumigraph / view-dependent texture mapping techniques.
- Derive geometry from images: As I mentioned, scanning specular objects is not particular easy. It would be good to skip this step by deriving the geometry directly from the images using some sort of multiview stereo algorithm. Unfortunately stereo isn't particularly easy to apply to shiny objects either, so this could be a challenging and interesting area of future work.
- Combining FQ and PFA: Function quantization uses a set of 0-dimensional subspaces to approximate the data, and PFA uses a single higher-dimensional space. If we use a set of higher-dimensional spaces (aka non-linear regression) we can hopefully achieve the best of both worlds.
|
 | We had fruitful discussion with the people listed here as well as others. We are also very grateful for the use of the Stanford Spherical Gantry. |
 | I'll end with a movie showing our two example surface light fields together at last. (And coincidentally showing compositing of surface light fields.) Any questions? (Actually, I'd also recommend reading the paper; it goes into a bit more detail than this talk.) |