Offline Policy Evaluation Across Representations with Applications to Educational Games
Abstract
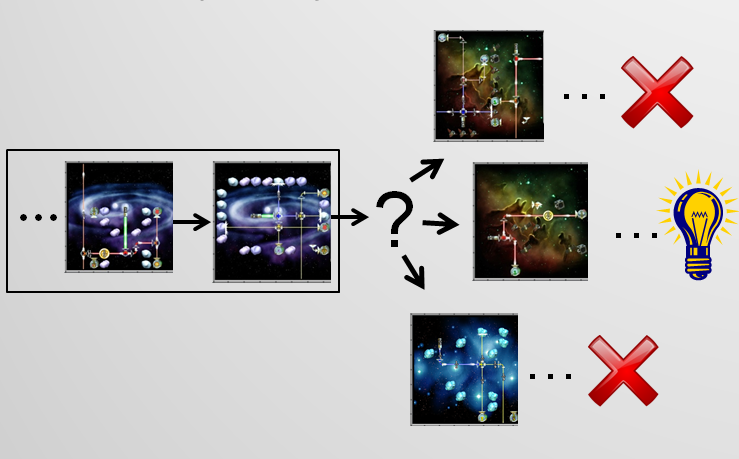
Consider an autonomous teacher agent trying to adaptively sequence material to best keep a student engaged, or a medical agent trying to help suggest treatments to maximize patient outcomes. To solve these complex reinforcement learning problems, we must first decide on a policy representation. But determining the best representation can be challenging, since the environment includes many poorly-understood processes (such as student engagement) and is therefore difficult to accurately simulate. These domains are also high stakes, making it infeasible to evaluate candidate representations by running them online. Instead, one must leverage existing data to learn and evaluate new policies for future use. In this paper, we present a data-driven methodology for comparing and validating policies offline. Our method is unbiased, agnostic to representation, and focuses on the ability of each policy to generalize to new data. We apply this methodology to a partially-observable, high-dimensional concept sequencing problem in an educational game. Guided by our evaluation methodology, we propose a novel feature compaction method that substantially improves policy performance on this problem. We deploy the best-performing policies to 2,000 real students and show that the learned adaptive policy shows statistically significant improvement over random and expert baselines, improving our achievement-based reward measure by 32%.
Authors
Resources