Abstract
Given a multi-microphone recording of an unknown number of speakers talking concurrently, we simultaneously localize the sources and separate the individual speakers. At the core of our method is a deep network, in the waveform domain, which isolates sources within an angular region \(\theta \pm w/2\), given an angle of interest \(\theta\) and angular window size \(w\). By exponentially decreasing \(w\), we can perform a binary search to localize and separate all sources in logarithmic time. Our algorithm also allows for an arbitrary number of potentially moving speakers at test time, including more speakers than seen during training. Experiments demonstrate state of the art performance for both source separation and source localization, particularly in high levels of background noise.
Comparisons
We show comparisons with existing methods on a challenging synthetic audio mixture. We only play one channel, but the experiment uses a virtual 6 microphone array. The perfect spectrogram mask shows the best possible performance for any method that operates on a magnitude spectrogram.
Input Mixture (2 Voices + BG)
|
|
|
|
|
|
|
|
| GT | Ours | TAC Beamformer [1] |
|---|
|
|
|
|
|
|
|
|
| Multi Channel Conv-TasNet [2] | Perfect Spectrogram Mask (Ratio) | Perfect Spectrogram Mask (Binary) |
|---|
[1] Y. Luo, Z. Chen, N. Mesgarani, and T. Yoshioka, “End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation,” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020.
[2] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019.
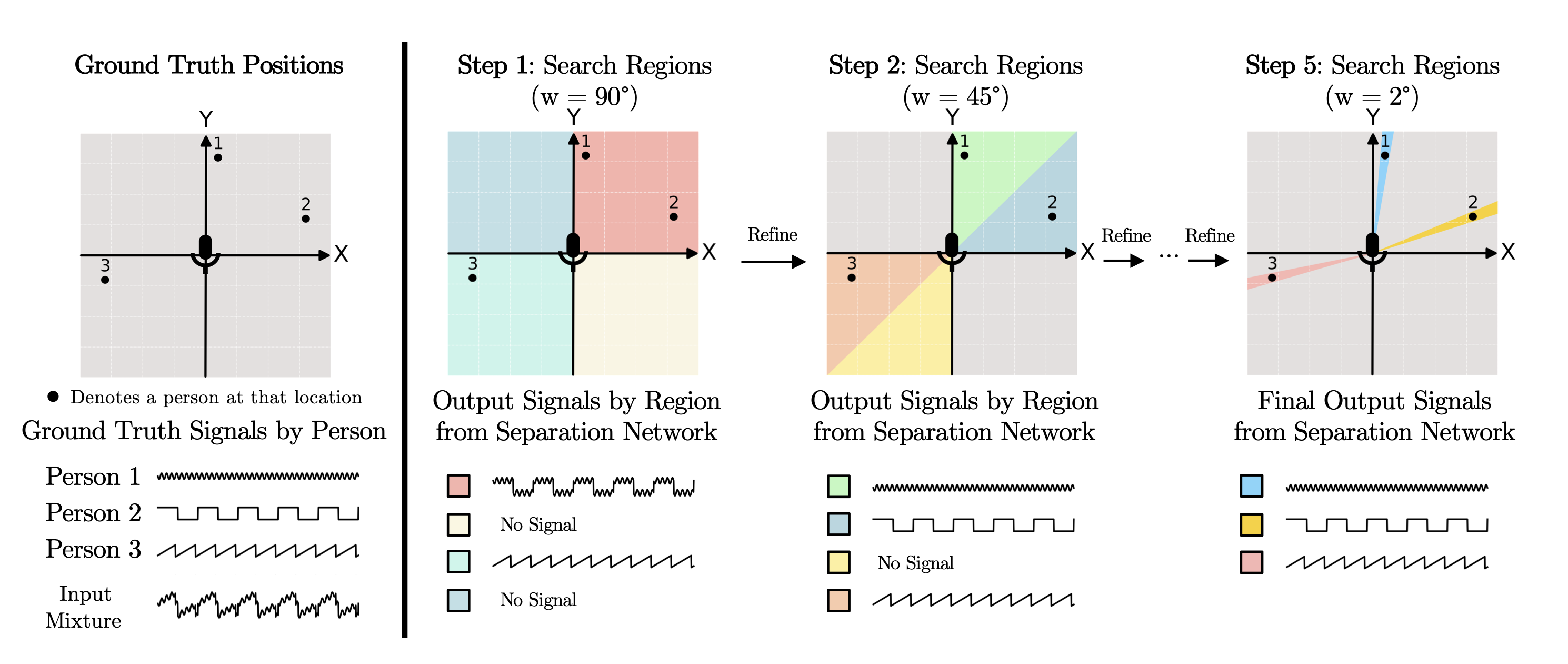
Interactive Visualization
In this interactive demo, we show output signals by region from the separation network. You can listen to the output of each region by clicking the respective region on the diagram.
Ground Truth Locations
Mixed signal
Ground Truths (played sequentially)
Network Output
Instructions:
1. Click on a region to hear network output from that region.
2. Click on Step 2 and later to see the refinement process.
Note: The dots represent the locations of speakers.
Source code
Training code and inference code available Here.
Citation
Contact and Info
UW GRAIL, UW Reality Lab, University of Washington
{tjenrung, vjayaram, seitz, kemelmi}@cs.washington.edu
Acknowledgements
The authors thank the labmates from UW GRAIL Lab. This work was supported by the UW Reality Lab, Facebook, Google, Futurewei, and Amazon.